고정 헤더 영역
상세 컨텐츠
본문
반응형
Title : Design and Evaluation Methods for LLM-Based Explainable AI (XAI)-Based Human-AI Collaboration Systems
최근 인공지능(AI) 기술의 발전은 다양한 산업 분야에 혁신적인 변화를 가져오고 있으며, 다양한 분야에서 인간의 업무를 지원할 수 있는 상당한 기회를 제공한다(Brynjolfsson & Mitchell, 2017; Perrault & Clark, 2024). 특히 딥러닝을 기반으로 한 AI 모델들은 복잡한 문제 해결에서 인간의 능력을 뛰어넘는 성능을 보여주고 있다. 또한, 다양한 분야에서 대규모 언어 모델(Large Language Models, LLMs)의 중요성을 부각시키고 있다(Jeong, 2025). 생성형 AI가 방대한 학습 데이터를 기반으로 텍스트, 이미지, 오디오, 비디오와 같은 새로운 콘텐츠를 생성할 수 있는 기술로, 이를 통해 사용자가 손쉽게 생성형 AI 서비스를 활용할 수 있게 되었다(Jeong C., 2023a; 2023b).
이렇게, 최근에 LLM 기반의 생성형 AI가 주목받으면서 Explainable AI (XAI)도 새로운 도전과 기회를 제공하고 있다. 예를 들어, 의료 진단 지원 시스템에서 AI는 복잡한 의료 영상 데이터를 분석한 후, 분석 근거를 단계별로 설명함으로써 의사의 판단을 보조할 수 있다. LLM들은 일반 딥러닝 모델들보다도 복잡한 구조, 많은 파라미터들 수 때문에 설명하기가 더욱 어렵다(Zhao et al., 2024). 이러한 AI 모델들은 대부분 '블랙박스' 형태로 작동하여, 그 의사결정 과정이 불투명하다는 한계를 가지고 있다. 이러한 불투명성은 AI 시스템에 대한 사용자들의 신뢰를 저해하고, 특히 의료, 금융, 법률과 같이 높은 신뢰성과 책임이 요구되는 분야에서는 AI 도입의 주요 장애물로 작용하고 있다.
이러한 배경에서 설명가능한 AI(XAI) 기술은 AI의 판단 근거를 인간이 이해할 수 있는 방식으로 제공함으로써, 시스템의 투명성, 공정성, 책임성을 강화하는 핵심 기술로 부상하고 있다.
특히 LLM과 Deep Research 기반 AI 에이전트의 등장으로 XAI는 새로운 국면에 진입하고 있다. 이들 모델은 단순 예측 결과 전달을 넘어 추론의 흐름, 오류 검증, 자연어 기반 설명 등 고차원적인 설명 특성을 포함함으로써, 기존 정적 XAI를 보완하고 있다. Deep Research 기능은 사용자의 질의에 대해 검색-분석-보고서 생성 과정을 다단계로 기록하며, 이를 통해 '과정 중심 XAI(process-centric XAI)'의 가능성을 제시하고 있다. 이러한 기술적 변화는 단순한 XAI 기술 개발을 넘어, 인간과 AI가 협력하여 더 나은 성과를 도출하는 인간-AI 협업 시스템(Human-AI Collaboration System)에 결정적인 영향을 미치고 있다. 특히 설명은 협업 상황에서 신뢰와 효율성을 결정짓는 핵심 요소로 작용한다.
인간과 AI가 상호 보완적으로 협력하는 인간-AI 협업 시스템은 AI의 강력한 문제 해결 능력과 인간의 직관, 경험, 윤리적 판단 능력을 결합하여 시너지를 창출할 수 있는 잠재력을 가지고 있다. 이러한 협업 시스템에서 AI의 의사결정 과정을 인간이 이해하고 신뢰할 수 있도록 설명하는 것은 필수적이다. 설명가능한 AI(Explainable AI, XAI)는 AI 모델의 내부 작동 방식과 예측 결과를 인간이 이해할 수 있는 형태로 제공함으로써, AI의 투명성과 신뢰성을 높이는 것을 목표로 한다. XAI 기술은 AI 시스템의 책임성을 확보하고, 잠재적인 편향성을 식별하며, 사용자에게 AI의 판단에 대한 통찰력을 제공하여 더 나은 의사결정을 돕는 데 기여할 수 있다. 이렇게 설명 가능한 인공지능(XAI)의 지원은 높은 성과를 내는 인간-XAI 팀의 가능성을 제공한다(Ece Kamar, 2016). 실제로, 인간-XAI 팀이 도전적인 의사결정 작업에서 상호 보완적인 성과를 달성할 것이라는 가정이 자주 이루어진다(Vasconcelos et al., 2022). 인간-XAI 팀이 인간이나 XAI 단독보다 더 나은 성과를 보일 것이라는 것이다 (Amershi et al., 2019; Bansal el al.,2019; Ece Kamar, 2016).
본 연구는 설명가능한 AI 기술을 인간-AI 협업 시스템에 통합하여, AI의 의사결정 과정을 인간에게 효과적으로 설명하고, 이를 통해 인간과 AI 간의 협업 효율성과 신뢰도를 향상시키는 방안을 모색하고 있다.
Deep Research 모델 비교
심층 연구(Deep Research) 모델은 아직 초기 단계에 있다. LLM 기반 XAI는 전통적인 XAI(예: SHAP, LIME)처럼 피처별 기여도(weight)를 수치로 명확히 제공하진 않습니다. 대신 논리적 설명, 단계별 reasoning, 중간결과 노출, 결론 정당화에 중점을 둔다. 또한, LLM에서 제공하는 설명은 때로 일관성이나 정확성에 할루시네이션이 있을수 있고, 추론 과정과 이유가 논리적이어 보일 수 있지만, 항상 "진실한 원인"이나 근거라는 보장이 어려운 한계점이 있다. 잘 연구된 답변에 빠르게 액세스할 수 있지만, 이러한 답변이 항상 신뢰할 수 있는 것은 아니다. 이러한 모델은 때때로 데이터를 잘못 해석하거나, 신뢰할 수 있는 출처와 루머를 섞거나, 불확실성을 강조하지 못할 수 있으나 지속적인 발전을 통해 신뢰할 수 있는 연구 도구가 될 수 있는 잠재력을 가지고 있다. 또한, 위와 같은 LLM-XAI 기능들은 인간 사용자의 이해를 도우며, 협업시스템에서 신뢰 확보에 기여할 수 있다.
Table 1. AI Model Deep Research Capability Comparison
| Feature | OpenAI's Deep Research | Perplexity’s Deep Research | Gemini's Deep Research |
| Overview | o3-powered assistant | Automated research | Faster AI assistant |
| Humanity's Last Exam benchmark | 26.6% accuracy | 21.1% accuracy | 6.2% accuracy |
| Technical Differentiation | Utilizing Reinforcement Learning | Leveraging Iterative Reasoning | Enabled Multi-layer Reasoning |
| User Experience & Accessibility | Limited Access (Pro users only) | User-friendly interface with free daily queries | A part of Gemini Advanced, a paid subscription |
Table 1에서 볼 수 있듯이, OpenAI, Google, Perplexity와 같은 주요 AI 기술 기업들은 이러한 흐름을 주도하며 AI의 연구 역량을 지속적으로 고도화하고 있다(Vina, 2025). 이들이 채택한 Deep Research 방식은 단일 고성능 에이전트가 순차적으로 심층 작업을 수행하는 구조를 갖는 반면, Manus가 2025년 8월에 발표한 Wide Research는 병렬 처리를 지원하는 시스템 수준의 메커니즘과 에이전트 간 협업을 위한 프로토콜을 도입하여, 수평적 확장과 다중 작업 협업에 중점을 두고 있다(Manus, 2025). 따라서, 보다 적극적인 XAI 적용을 위해서는 에이전트 간 협업뿐 아니라 인간-AI 협업을 통한 지속적인 설명력 강화와 발전이 필수적이다.
인간-AI 협업 시스템
HAIC (Human-AI Collaboration)는 문제 해결, 통찰력 창출, 그리고 가치 창출을 위해 인간과 AI의 상호 보완적인 강점을 활용하는 유망한 패러다임으로 부상하고 있다(Song el al., 2024). 이는 다양한 맥락에서 하이브리드 지능(Dellermann et al., 2019), 하이브리드 인간-AI 팀 구성(Caldwell et al., 2022), 그리고 슈퍼팀(AI를 팀에 통합하는 것)(Deloitte, 2020) 등으로 불려 왔다. HAIC 시스템은 인간의 고유한 능력(창의성, 비판적 사고, 윤리적 판단 등)과 AI의 강점(대규모 데이터 처리, 패턴 인식, 빠른 연산 등)을 결합하여 시너지를 창출하는 시스템을 의미한다. 이러한 시스템은 단순히 AI가 인간의 작업을 자동화하거나 보조하는 것을 넘어, 인간과 AI가 상호작용하며 공동의 목표를 달성하는 데 초점을 맞춘다. 인간-AI 협업은 다양한 분야에서 그 잠재력을 인정받고 있으며, 특히 복잡하고 불확실한 환경에서 최적의 의사결정을 내리는 데 효과적이다.
인간-AI 협업 시스템의 핵심은 인간과 AI 간의 효과적인 상호작용과 정보 교환이다. AI는 데이터를 분석하고 패턴을 식별하여 통찰력을 제공하며, 인간은 이러한 통찰력을 바탕으로 최종 결정을 내리거나 AI의 제안을 수정, 보완한다. 이 과정에서 AI의 역할은 단순히 도구를 제공하는 것을 넘어, 인간의 인지적 부담을 줄이고 의사결정의 질을 향상시키는 데 기여해야 한다. 성공적인 인간-AI 협업을 위해서는 AI의 능력과 한계를 인간이 명확히 이해하고, AI 또한 인간의 의도와 맥락을 파악할 수 있어야 한다.
협업의 형태는 다양하게 나타날 수 있다. 예를 들어, AI가 초안을 생성하고 인간이 이를 검토 및 수정하는 Human-in-the-loop 방식, AI가 자율적으로 작업을 수행하되 중요한 결정은 인간의 승인을 받는 Human-on-the-loop 방식, 그리고 AI가 인간의 감독 없이 독립적으로 작업을 수행하는 Human-out-of-the-loop 방식 등이 있다. 최근에는 생성형 AI와 OCR/IDP, 그리고 Automation Agent를 유기적으로 결합하여 Human-in-the-loop 메커니즘을 통해 담당자의 최종 판단이 시스템에 반영되어 인간-AI협업한 자동화 성능이 향상되도록 제안한 연구도 활발히 이루어 지고있다(Jeong et al., 2025, Jeong, 2023c).
본 연구에서는 특히 인간이 AI의 의사결정 과정에 적극적으로 참여하고, AI의 설명을 통해 상호 이해를 증진시키는 협업 모델에 초점을 맞춘다.
인간-AI 협업 시스템의 성공적인 구현을 위해서는 다음과 같은 요소들이 중요하게 고려되어야 한다:
● 상호 이해 (Mutual Understanding): 인간은 AI의 작동 방식과 한계를 이해하고, AI는 인간의 목표, 선호도, 인지적 특성을 이해해야 한다.
● 신뢰 (Trust): 인간이 AI의 제안을 신뢰하고 받아들일 수 있도록 AI의 예측에 대한 근거와 불확실성을 명확히 제시해야 한다.
● 효과적인 의사소통 (Effective Communication): AI가 인간에게 정보를 전달하는 방식은 직관적이고 이해하기 쉬워야 하며, 인간의 피드백을 AI가 효과적으로 수용할 수 있어야 한다.
● 역할 분담 및 책임 (Role Allocation and Responsibility): 인간과 AI의 역할이 명확히 정의되고, 각자의 책임 범위가 설정되어야 한다.
이러한 요소들은 설명가능한 AI 기술을 인간-AI 협업 시스템에 통합함으로써 더욱 강화될 수 있다. AI의 설명을 통해 인간은 AI의 의사결정 과정을 더 깊이 이해하고, 이는 곧 AI에 대한 신뢰 증진과 효율적인 협업으로 이어질 수 있다.
XAI 기반 인간-AI 협업 시스템 연구는 다음과 같은 주요 주제들을 다루고 있습니다:
● 설명 유형 및 형식의 최적화: AI의 설명을 어떤 유형(예: 규칙 기반, 사례 기반, 특징 중요도)과 형식(예: 텍스트, 시각화)으로 제공해야 인간이 가장 효과적으로 이해하고 활용할 수 있는지에 대한 연구가 진행되고 있다. 사용자의 인지적 특성, 작업의 복잡성, 도메인의 특성 등을 고려한 맞춤형 설명 제공 방안이 모색되고 있다.
● 인간-AI 상호작용 설계: AI 설명을 인간에게 효과적으로 전달하고, 인간의 피드백을 AI가 반영할 수 있는 사용자 인터페이스(UI) 및 사용자 경험(UX) 설계에 대한 연구가 중요하게 다루어지고 있다. 직관적이고 사용하기 쉬운 인터페이스는 인간과 AI 간의 원활한 소통을 가능하게 한다.
● 신뢰 및 의존도 관리: XAI는 AI에 대한 인간의 신뢰를 높이는 데 기여하지만, 과도한 신뢰나 불신은 협업의 효율성을 저해할 수 있다. 따라서 XAI를 통해 적절한 수준의 신뢰를 구축하고, AI에 대한 인간의 의존도를 균형 있게 관리하는 방안에 대한 연구가 필요한다.
● 다중 모달리티 XAI: 텍스트, 이미지, 음성 등 다양한 형태의 데이터를 처리하는 다중 모달 AI 시스템에서 통합적인 설명을 제공하는 XAI 기술에 대한 연구도 활발한다. 이는 더욱 복잡하고 현실적인 AI 시스템에 XAI를 적용하기 위한 필수적인 단계이다.
● 책임성 및 윤리적 고려: XAI는 AI 시스템의 책임성을 확보하고 윤리적 문제를 해결하는 데 중요한 도구로 인식되고 있다. AI의 의사결정 과정을 투명하게 공개함으로써 편향성, 차별 등의 문제를 식별하고 개선하는 데 기여할 수 있다.
시스템 아키텍처
제안하는 설명가능한 AI 기반 인간-AI 협업 시스템은 <그림 1>과 같은 아키텍처를 가진다. 이 아키텍처는 AI 모델, 설명 생성 모듈, 인간-AI 인터페이스, 그리고 인간 사용자라는 네 가지 주요 구성 요소로 이루어져 있다.
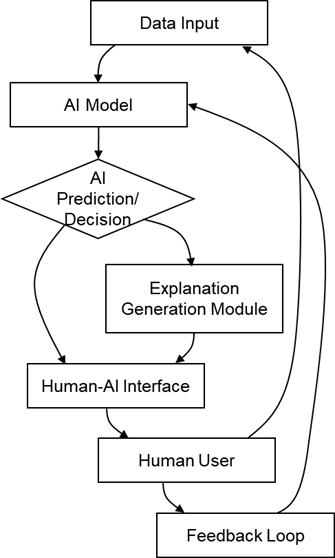
Figure 1. Explainable AI-Based Human-AI Collaboration System Architecture
● 데이터 입력 (Data Input): 시스템이 처리할 원시 데이터(예: 이미지, 텍스트, 센서 데이터)가 입력되는 부분이다. 이 데이터는 AI 모델의 예측 또는 결정을 위한 기반이 된다.
● AI 모델 (AI Model): 특정 태스크를 수행하고 예측 또는 결정을 내리는 핵심 인공지능 모델이다. 이 모델은 딥러닝, 머신러닝 등 다양한 AI 기술을 기반으로 할 수 있으며, 본 연구에서는 특히 설명이 필요한 복잡한 블랙박스 모델을 가정한다.
● AI 예측/결정 (AI Prediction/Decision): AI 모델이 데이터 입력을 처리한 후 생성하는 최종 결과물이다. 이는 분류 결과, 예측 값, 추천 등 다양한 형태를 가질 수 있다.
● 설명 생성 모듈 (Explanation Generation Module): AI 모델의 예측 또는 결정에 대한 설명을 생성하는 핵심 모듈이다. 이 모듈은 AI 모델의 내부 작동 방식, 입력 데이터의 특징, 예측에 영향을 미친 주요 요인 등을 분석하여 인간이 이해하기 쉬운 형태로 설명을 생성한다. LIME, SHAP, Grad-CAM 등 다양한 XAI 기법이 이 모듈에 통합될 수 있다. 생성된 설명은 인간-AI 인터페이스를 통해 인간 사용자에게 전달된다.
이 모듈은 Table 3과 같이 LLM의 자연어 생성 능력과 Deep Research 기능을 활용하여 Chain-of-Thought 기반의 추론 흔적, 자연어 설명, 다단계 검증 메커니즘 등을 제공한다.
Table 3. 설명 유형 및 사용자 이점
| 설명 유형 | 설명 방식 | 사용자 이점 |
| 과정 중심 설명 | AI의 추론 과정(Chain-of-Thought) 단계별 제시 | AI 의사결정 과정의 투명성 확보, 신뢰 증진 |
| 자연어 설명 | 사람이 이해하기 쉬운 자연어로 설명 제공 | 비전문가도 쉽게 이해, 인지적 부담 감소 |
| 다단계 검증 | AI의 판단 근거 및 중간 결과 검증 과정 제시 | 설명의 신뢰성 및 정확성 향상 |
| 반사실적 설명 | 입력값 변화에 따른 예측 결과 변화 시뮬레이션 | 모델의 민감도 이해, 잠재적 위험 파악 |
● 인간-AI 인터페이스 (Human-AI Interface): 사용자가 AI의 설명을 직관적으로 이해하고, 시스템과 효과적으로 상호작용할 수 있도록 설계된다. 주요 인터페이스 기능은 다음과 같다
• 설명 시각화: 특징 중요도 그래프, Grad-CAM 기반 히트맵 등 시각 자료 제공
• 설명 유형 선택: 사용자가 특징 기반/규칙 기반/사례 기반/반사실적 설명 중 선택 가능
• 설명 수준 조절: 요약 모드와 상세 모드 전환 가능
• 피드백 제공: 설명 유용성 평가, 수정 제안, 추가 질의 기능 제공
• 맥락 인지: 긴급 상황 시 핵심 정보만 제공, 분석 상황에서는 상세 정보 제공
이러한 설계는 기존 연구에서 지적된 한계점, 즉 정적인 설명 제공과 사용자 요구사항에 대한 적응성 부족 문제를 해결하는 데 기여할 것이다.
● 인간 사용자 (Human User): AI 시스템과 협업하는 주체이다. 인간 사용자는 AI의 예측과 설명을 바탕으로 최종 의사결정을 내리거나, AI의 작업을 감독하고 필요한 경우 개입한다.
● 피드백 루프 (Feedback Loop): 인간 사용자가 AI의 예측, 결정, 또는 설명에 대해 제공하는 피드백이 AI 모델의 학습 또는 설명 생성 모듈의 개선에 활용되는 핵심 경로이다. 본 시스템의 피드백 루프는 단순한 데이터 수집을 넘어, HITL 원칙을 기반으로 사용자 검증, 도메인 전문가의 수정, 그리고 맥락적 제약을 통합하여 AI 모델의 런타임 재학습 결정(runtime retraining decisions)을 감독한다. 이는 통계적 드리프트(statistical drift)에만 의존하는 자동화된 재학습 트리거의 한계를 넘어, 인간의 판단과 전문성을 시스템 개선 과정에 적극적으로 통합한다. 이처럼 인간의 피드백이 시스템에 반영되는 과정은 시스템의 지속적인 개선과 인간-AI 협업의 적응성을 보장하며, AI의 진화를 자율적인 알고리즘 루틴이 아닌 협력적 과정으로 재정의한다. 피드백은 명시적(예: 사용자 평가, 주석 도구 활용)이거나 암묵적(예: 사용자의 행동 패턴 분석, 설명 탐색 시간)일 수 있으며 , 이 피드백은 설명 생성 모듈의 최적화와 인터페이스의 적응성을 위한 중요한 자원이 된다. 이러한 HITL 기반의 피드백 메커니즘은 AI 시스템의 성능, 안전성, 윤리적 행동을 향상시키는 데 기여하며, 궁극적으로 인간과 AI 간의 신뢰를 공고히 하는 데 필수적인 역할을 한다.
LLM-XAI 기반 인간-AI 협업시스템의 평가지표
AI가 제공하는 설명의 유용성과 이해도는 인간 사용자의 이해도와 신뢰도에 직접적인 영향을 미치므로, 설명의 품질을 체계적으로 측정하는 것이 중요하다. 설명 이해도, 유용성, 신뢰도는 설문 조사나 인터뷰를 통해 주관적으로 평가될 수 있으나, 설명 품질에 대한 객관적이고 정량적인 지표 개발은 XAI 연구의 중요한 과제이자 본 연구의 기여점이 될 수 있다. XAI 평가 방법론의 표준화가 부족하다는 점은 학계에서 지속적으로 지적되고 있으며, 사용자 중심의 평가로의 전환이 강조되고 있다.
따라서, 제안하는 시스템의 설명 품질을 보편적으로 검증할 수 있는 방법론 제시가 요구된다. 예를 들어, 설명이 모델의 동작을 얼마나 정확하게 반영하는지(Faithfulness, Fidelity), 입력값의 작은 변화에 설명이 얼마나 일관되게 반응하는지(Robustness, Stability), 설명이 얼마나 간결하고 필요한 정보만을 포함하는지(Compactness, Sufficiency) 등을 측정하는 지표를 고려할 수 있다. 또한, 설명이 사용자에게 새로운 지식을 제공하는 정도(Learning), 특정 작업을 수행하는 데 얼마나 도움이 되는지(Utility), 사용자의 설명 요구를 얼마나 충족시키는지(Fulfillment), 그리고 시스템과의 상호작용에 얼마나 몰입하게 하는지(Engagement) 등을 포괄하는 XAI Experience Quality (XEQ) Scale과 같은 사용자 중심 평가 프레임워크를 활용할 수 있다. 이러한 객관적, 정량적 지표와 사용자 중심의 평가 프레임워크를 통합적으로 활용함으로써, 설명의 품질을 보다 다각적이고 엄밀하게 평가할 수 있다.
Table 5. XAI 설명 품질 평가를 위한 주요 지표 및 측정 방법
| 구분 | 지표 항목 | 정의 설명 | 측정 방법 |
| Objective (객관적) |
충실성 (Faithfulness) | 설명이 AI 모델의 실제 내부 작동 방식이나 예측 결과를 얼마나 정확하게 반영하는가. | Insertion 및 Deletion AUC 테스트 (하이라이트된 영역이 모델 결정에 미치는 영향 평가) |
| 일관성/견고성 (Consistency/Robustness) | 입력값의 작은 변화에도 설명이 얼마나 일관되게 유지되는가. | 입력 데이터 섭동(perturbation)에 따른 설명 변화 분석 | |
| 간결성 (Compactness/Sufficiency) | 설명이 불필요한 정보 없이 핵심적인 내용만을 포함하는가. | 설명의 길이, 정보 밀도 평가, 사용자 인지 부하 측정 | |
| Subjective (주관적) |
설명 이해도 (Understandability) | 사용자가 AI의 설명을 얼마나 명확하게 이해하는가. | 설문 조사(Likert 척도), 인터뷰, 설명 내용을 바탕으로 한 객관식 질문 |
| 설명 유용성 (Usefulness) | AI의 설명이 사용자의 의사결정이나 작업 수행에 얼마나 도움이 되는가. | 사용자의 주관적 평가, 설명 제공 전후 의사결정 품질 변화 비교 | |
| 설명 신뢰도 (Trustworthiness) | 사용자가 AI의 설명을 얼마나 신뢰하는가 (AI 모델 자체 신뢰도와 구분). | 설문 조사(Hoffman Trust Scale 등), 인터뷰 | |
| 학습 (Learning) | 설명이 사용자에게 새로운 지식이나 통찰력을 제공하는가. | 작업 수행 전후 지식 수준 변화 측정, 사용자 학습 경험 평가 | |
| 만족도 (Satisfaction) | 설명 경험에 대한 사용자의 전반적인 만족도. | 설문 조사(XEQ Scale 등), 인터뷰 | |
| 참여도 (Engagement) | 사용자가 설명 시스템과 얼마나 능동적으로 상호작용하고 몰입하는가. | 시스템 로그 분석(설명 탐색 시간, 기능 사용 빈도), 설문 조사 |
Table 5는 XAI 설명의 품질을 평가하기 위한 주요 지표들을 포괄적으로 제시하며, 각 지표의 정의와 측정 방법을 명시한다. 이는 본 연구의 평가 방안을 더욱 구체화하고, 설명 품질에 대한 객관적이고 사용자 중심적인 접근 방식을 강조하는 데 기여한다.
본 연구는 대규모 언어모델(LLM) 기반 설명가능한 인공지능(XAI)을 적용한 인간-AI 협업 시스템에 대해, 기존의 단순 정답률 기반 평가를 넘어 설명성 중심의 다차원적 평가 기준을 도입하였다. 특히, LLM이 자체적으로 생성한 추론 과정과 자연어 설명, 그리고 사용자의 피드백 루프와의 상호작용을 포괄적으로 고려하여, 협업 시스템 내 실질적인 이해도와 신뢰성 확보 여부를 중심으로 진단하고자 하였다. 평가는 인간-AI 협업 과정에서의 설명성, 신뢰성, 투명성 등 핵심 품질 속성을 중심으로 이루어지며, LLM 기반의 추론흔적 제공, 다단계 검증, 하이브리드 설명 방식 등이 반영된 점을 고려한다. 평가지표는 Table 6과 같이 설명가능성(Explainability), 투명성(Transparency), 정확성(Correctness), 신뢰성(Trustworthiness), 그리고 상호작용성(Interactivity)과 사용자 적응성(Adaptability)으로 구성된다.
각 항목은 시스템이 얼마나 효과적으로 자신의 판단 근거를 사용자에게 전달하고, 사용자의 질의나 피드백에 대해 실시간으로 반응하며, 오류 가능성을 사전에 검증하거나 설명을 동적으로 조절할 수 있는지를 중심으로 설계되었다. 또한, 사용자의 이해도, 신뢰도, 활용의도 등을 반영한 정성적 설문 및 전문가 평가와, 설명 단계 수나 추론 로그 노출 여부, 결과 오류율 등 정량적 로그 기반 측정 데이터를 병행 적용한다. 이를 통해 단순히 정답률만을 평가하는 기존 모델과 달리, 과정 중심의 설명 품질, 사용자 경험 기반의 상호작용성, 그리고 AI 자체 검증 기능의 적절성 등을 포함하는 다면적 평가 체계를 구현한다.
Table 6. LLM-XAI 기반 인간-AI 협업 시스템의 평가지표
| 지표 항목 | 지표 정의 | 지표 측정 방법 |
| 설명가능성 (Explainability) | 시스템이 제공하는 결과 또는 행동에 대해 사용자가 "왜 그런 결과가 나왔는지" 이해할 수 있도록 설명해주는 정도 | - 추론 과정에 대한 자연어 설명 유무 - 설명 단계 수 (Chain-of-Thought 단계 기록 여부) - 사용자 설문을 통한 설명 이해도 평가 (Likert scale 1~5) - 전문가 평가단에 대한 설명 논리성 정성분석 |
| 투명성 (Transparency) | AI의 내부 추론 흐름, 정보 출처, 오류 발생 이유 등이 사용자에게 얼마나 드러나는지를 의미 | - 중간 추론 결과 노출 빈도 - 근거 자료 인용 여부(출처 링크 수 등) - 오답 또는 실패 경우 실패 사유 기재 여부 - 사용자에게 노출된 '추론 흔적(trace)' 수 |
| 신뢰성 (Trustworthiness) | 사용자(전문가/비전문가 포함)가 AI 시스템의 판단을 신뢰할 수 있는 정도 | - 사용자 대상 신뢰도 설문 (e.g., “해당 시스템을 실제 업무에서 사용할 의향이 있습니까?”) - 결과 변경 시 논리적 이유 제시 비율 - 추론결과 오류율 / 수정율 (검토자 또는 사용자 로그 기반) |
| 정밀성/정확성 (Correctness) | 시스템이 생성한 정보 또는 판단이 실제 논리 및 데이터에 기반하고 오류가 적은지에 대한 정량적 정확도 | - 생성된 결과의 정답률 또는 전문가 평가 점수 - 팩트체크 기반 정확률 (%단위) - 외부 평가자(도메인 전문가)에 의한 진위 판단 |
| 상호작용성 (Interactivity) | 사용자와 AI 간의 실시간 질의·반응, 피드백, 수정 요청 등의 상호작용 기능 및 품질 | - 피드백 입력 후 AI 응답 시간 - 사용자 인터페이스 내 피드백 또는 반론 기능 제공 여부 - 단일 질의에 대한 사용자–AI 반복 대화 횟수 평균 |
| 적응성 / 맞춤화 정도 (Adaptability) | 사용자 수준(전문가/비전문가, 배경 지식 등)에 맞춰 설명 형식이나 추론 수준을 얼마나 동적으로 조절하는가 | - 사용자 정의 설정에 따른 설명 변화 유무 (예: 상세 vs 요약 모드 선택) - 동일 질문에 대해 사용자 유형별 설명 방식 차이 - 인터페이스 로그 기반 사용자 세분화 반응률 |
| 검증 기능성 (Self-Verification Capability) | AI 시스템이 스스로 오류나 불확실성을 감지하고 사용자에게 경고하거나 근거를 보완하는 능력 | - "검증 실패" 또는 "신뢰도 낮음" 표기 횟수 - 검증 Agent 응답 비중 또는 실패 모델링 비율 - 결론 제시 이전의 근거 보완 또는 자기점검 여부 (trace-trigger 로그 분석) |
* 출처: DOI: 10.54364/AAIML.2025.53240
반응형
'IT논상' 카테고리의 다른 글
| LLM 기반 자율 멀티에이전트 시스템의 상호운용성을 위한 실용적 MCP×A2A 통합 프레임워크 (0) | 2025.10.10 |
|---|---|
| 멀티모달 LLM 기반 멀티 에이전트 시스템 구현: No-Code 플랫폼 활용 (8) | 2025.01.07 |
| Graph Agent 활용한 Advanced RAG 시스템 구현 방법 (12) | 2024.10.01 |
| 도메인 특화 LLM 파인튜닝 절차 (3) | 2024.05.21 |
| RAG모델과 LangChain 프레임워크 기반 LLM 서비스 구현 방법 (3) | 2024.05.21 |





댓글 영역