고정 헤더 영역
상세 컨텐츠
본문
반응형
최근 몇 년 동안, 인공지능과 딥러닝 기술의 발전으로 인해 특히, 자연어 처리 분야에서 놀라운 성과를 얻고 있다. 그 중에서도 대규모 언어 모델(Large Language Models, LLM)은 풍부한 문맥과 언어 이해 능력으로 인간 수준의 언어 생성 및 이해에 도달하고 있다. 따라서 여러 산업군에서 LLM도입을 활발히 검토하거나 도입하고 있다.
특히, McKinsey에 따르면 LLM 등 생성형 AI는 은행업 내에서 ‘마케팅/판매, 고객지원/관리, 프로그래밍, 규제준수’ 비즈니스 분야에서 생산성 제고에 기여할 것으로 보고 있다. 생성형 AI는 글로벌 은행산업 내에서 약 2,000억~3,400억 달러의 가치를 창출할 것으로 전망되며, 이는 산업 전체의 매출 에서 2.8~4.7%에 상응하는 수치다. 금융회사는 내부적으로 직원의 업무 수행을 지원하고 자동화 하며, 자연어 기반 정보를 수집・분석해 전략적 판단을 내리기 위하여 LLM을 활용한다(장갑수, 2023). 이렇게 가장 늦게 신기술을 도입하는 금융권에서도 생성형 AI인 LLM의 활용이 확대되고 있다. 하지만 일반적인 LLM을 가지고 도입을 검토하기 때문에 금융권의 특화된 요구사항을 충족시키는데 한계가 있다. 도메인 특화는 특정 분야에 깊은 지식을 갖춘 LLM을 개발하는 것을 목표로 하는데 해당 분야의 특화된 요구사항을 충족하는 것이 필수적이다. 예를 들어, 의료 분야에서는 정확하고 상세한 의학 용어와 지식이 필요하며, 법률 분야에서는 복잡한 법률 용어와 개념을 정확히 이해하고 처리할 수 있는 능력이 요구된다. 이러한 특화된 요구사항을 충족시키기 위해서는 일반적인 LLM보다는 해당 분야에 특화된 모델이 필요하며 해당 분야의 세밀한 요구사항을 만족시키고, 보다 정확하고 신뢰할 수 있는 결과를 제공하는 데 중요한 역할을 해야 한다.
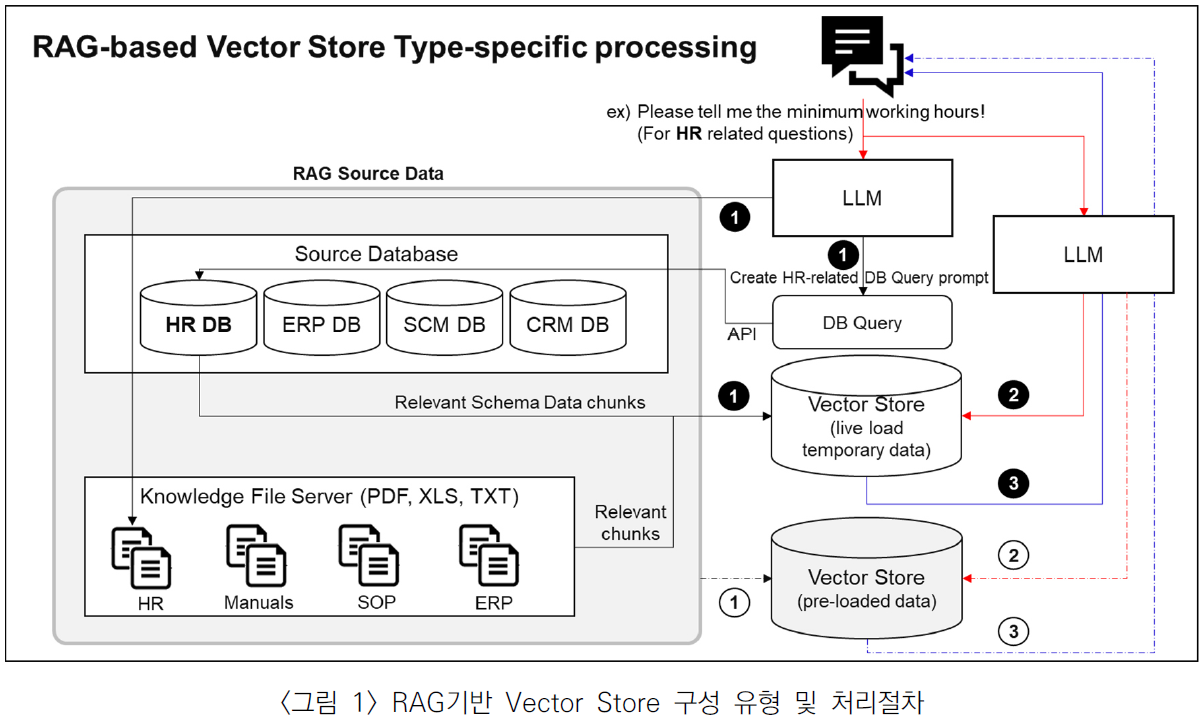
특히 금융분야에서는 고객 응대 챗봇을 통한 최신 정보 제공의 중요성에 대두되며, LLM의 정보 제한성과 환각(Hallucination) 문제는 이러한 모델들의 도전 과제로 지적되고 있다. 이를 해결하기 위한 접근방식으로는 새로운 데이터로의 파인튜닝과 프롬프트 콘텍스트에 직접 정보를 삽입하는 방안이 있으나, 파인튜닝의 경우에 학습을 위한 인프라 준비 등 상당한 비용이 발생하며, 모든 정보를 프롬프트에 넣어주는 것도 현실적으로 어렵기 때문에 이에 대안으로 RAG모델이 제안되었으며, <그림 1>과 같이 정보를 벡터 데이터베이스에 저장하고, 필요한 정보를 검색하여 LLM에 전달 하는 방식으로 구현되기도 한다(정천수, 2023d).
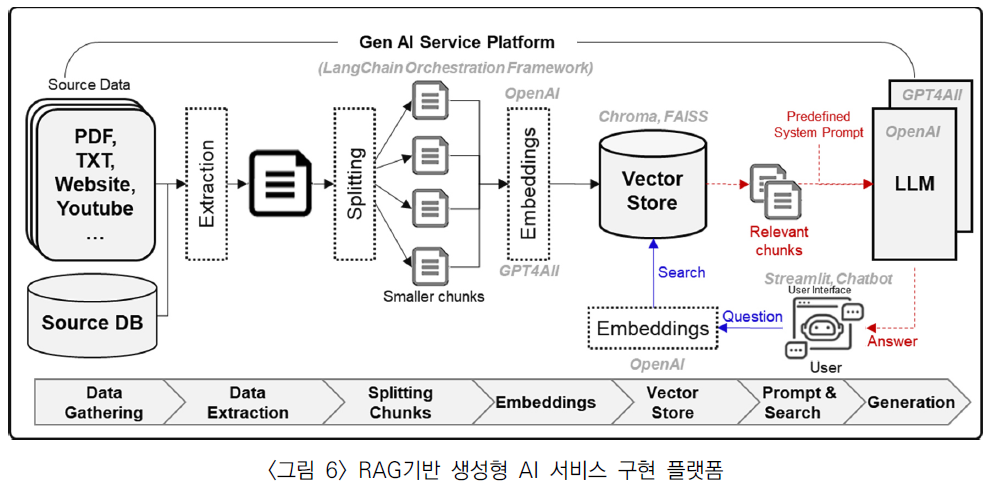
프레임워크를 통해 소스 데이터로부터의 정보 추출 및 LLM의 활용 절차까지 나타내고 있다. 과정은 문서에서 정보를
추출하여 소규모 청크로 분할하고, 이를 임베딩하여 벡터 데이터베이스에 저장하는 것으로 시작한다. 사용자의 질문이 임베딩된 후, 질문과 유사한 벡터를 저장소에서 검색하여 LLM에 전달되고, LLM은 이러한 청크들을 조합하여 사용자
정의 데이터로부터 응답을 생성해 제공한다.
* 출처 : Generative AI service implementation using LLM application architecture: based on RAG model and LangChain framework
반응형
'IT논상' 카테고리의 다른 글
| Graph Agent 활용한 Advanced RAG 시스템 구현 방법 (12) | 2024.10.01 |
|---|---|
| 도메인 특화 LLM 파인튜닝 절차 (3) | 2024.05.21 |
| Fine-tuning and Utilization Methods of Domain-specific LLMs (3) | 2024.03.05 |
| LLM 애플리케이션 아키텍처를 활용한 생성형 AI 서비스 구현: RAG모델과 LangChain 프레임워크 기반 (4) | 2024.02.06 |
| Implementation of Generative AI Services Using an Enterprise Data-Based LLM Application Architecture (4) | 2024.02.06 |





댓글 영역